Google’s Gemini AI model simplifies API onboarding by automatically generating comprehensive “Get Started” tutorials with code snippets, making it easier for developers to quickly understand and use your APIs. This results in faster adoption and a more successful API ecosystem.
Building on this, part 1 of this guide showed you how to use Gemini to create Python tutorials for your APIs. In part 2, we’ll take it further by automating this process at scale using Gemini 1.5 Pro on Vertex AI. By simply uploading your OpenAPI Specification to a Google Cloud Storage (GCS) bucket, you can automatically generate “Get Started” Python tutorials in Markdown format for all your APIs in another GCS bucket.
This automated approach is perfect for integrating into your existing workflows, such as automatically generating tutorials for new APIs as they are published to your developer portal. If you haven’t already, check out part 1 for a deeper understanding of how to prompt Gemini effectively.
Let’s get started.
High Level Architecture
The diagram below shows a high level architecture of our solution. This architecture leverages Google Cloud Functions and AI capabilities (Vertex AI with Gemini) to automate the creation of tutorials, streamlining the onboarding process for developers using the APIs.
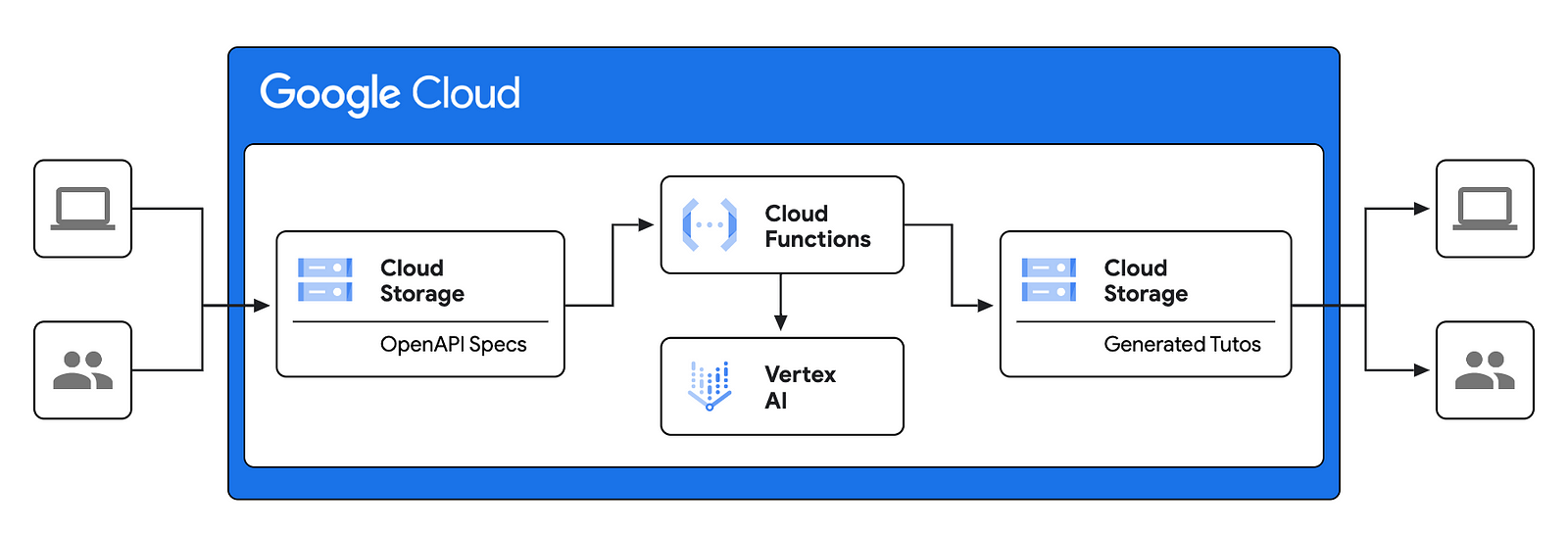
Let’s have a closer look at the different building blocks of this architecture:
- OpenAPI Specs (Cloud Storage): The process begins with the upload of OpenAPI Specifications (detailed API descriptions) to a Google Cloud Storage bucket. This acts as the input source for the tutorial generation process.
- Cloud Functions: A Cloud Function is triggered whenever new OpenAPI specs are uploaded to the storage bucket. This function serves as the orchestrator of the workflow.
- Vertex AI: The Cloud Function invokes Vertex AI (Python SDK) to process the OpenAPI specs and generate the “Get Started” tutorials.
- Generated Tutos (Cloud Storage): The generated tutorials, likely in markdown (.md) format, are then stored in a separate Cloud Storage bucket.
- Users: These tutorials can then be integrated into a developer portal.
In summary, this architecture leverages Google Cloud’s serverless (Cloud Functions) and AI capabilities (Vertex AI with Gemini) to automate the creation of tutorials, streamlining the onboarding process for developers using the APIs.
Now let’s deep-dive into the implementation details.
Step-by-Step Tutorial
In the following we will cover a “PoC” implementation of the architecture shown above in GCP.
Note: Ensure you have a Google Cloud Platform (GCP) project with billing enabled. Verify that all necessary GCP APIs for this tutorial are enabled in your project.
Cloud Storage
Create two buckets, one for storing the OpenAPI specification files (input) and another for storing the generated tutorials (output).

These two buckets will be used as follows:
- my-api-specs: Will be used to upload our Open API Specs. You can create folders if you want to better organize your Open API Specs.
- my-api-tutos: The “Get Started” tutorials will be written to a folder called “python-tutos” within this bucket.
Vertex AI
Navigate to“Vertex AI” in your GCP console and click on “Language” in the left menu under “Vertex AI Studio”, then click on “Text Prompt” as shown below.
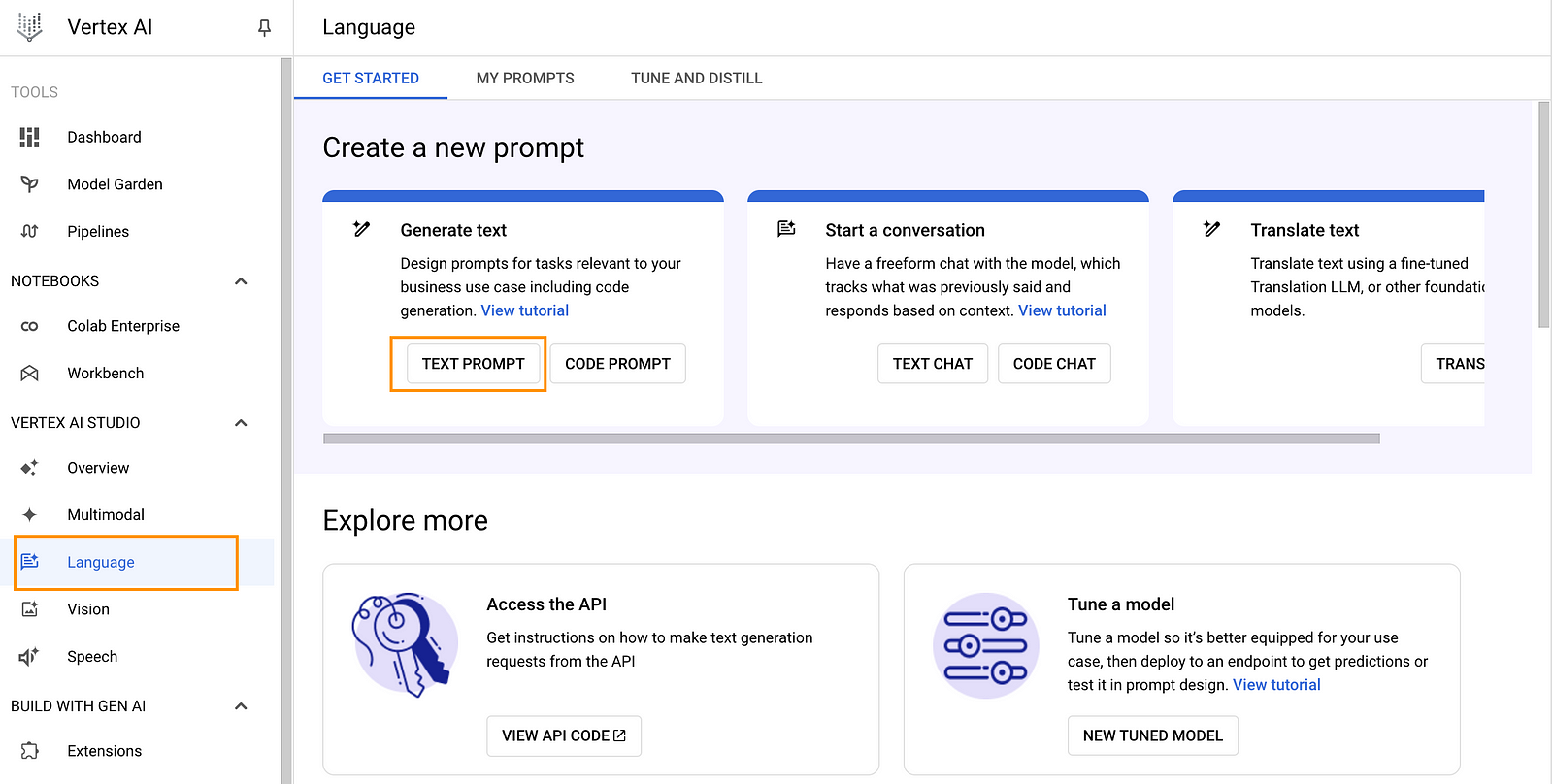
I reused the same prompt and OpenAPI Specification as in part 1 of this guide.
You are an expert API developer specializing in Python.
Your task is to create a comprehensive "Get Started" tutorial using the OpenAPI Specification 3.0 (provided below).
Please focus on the following key elements:
Clear Explanations: Provide step-by-step instructions on how to use the API effectively.
Explain the purpose of each endpoint and the structure of requests and responses.
Python Code Snippets: Include well-structured, easy-to-understand Python code examples demonstrating how to interact with each API endpoint. Cover authentication, request formatting, error handling, and response parsing.
Response Interpretation: Guide users on how to interpret API responses, including handling different response codes, extracting relevant data, and utilizing it in their applications.
Best Practices: Incorporate API development best practices, security considerations, and potential optimizations for Python users.
Please note:
The target audience is Python developers who are new to this specific API.
Prioritize clarity, conciseness, and practical examples.
The tutorial should be self-contained, with minimal external dependencies.
OpenAPI Specification:
{INSERT YOUR OPEN API SPEC HERE}
Feel free to adjust the prompt and model parameters to your liking. Here are the settings I used:
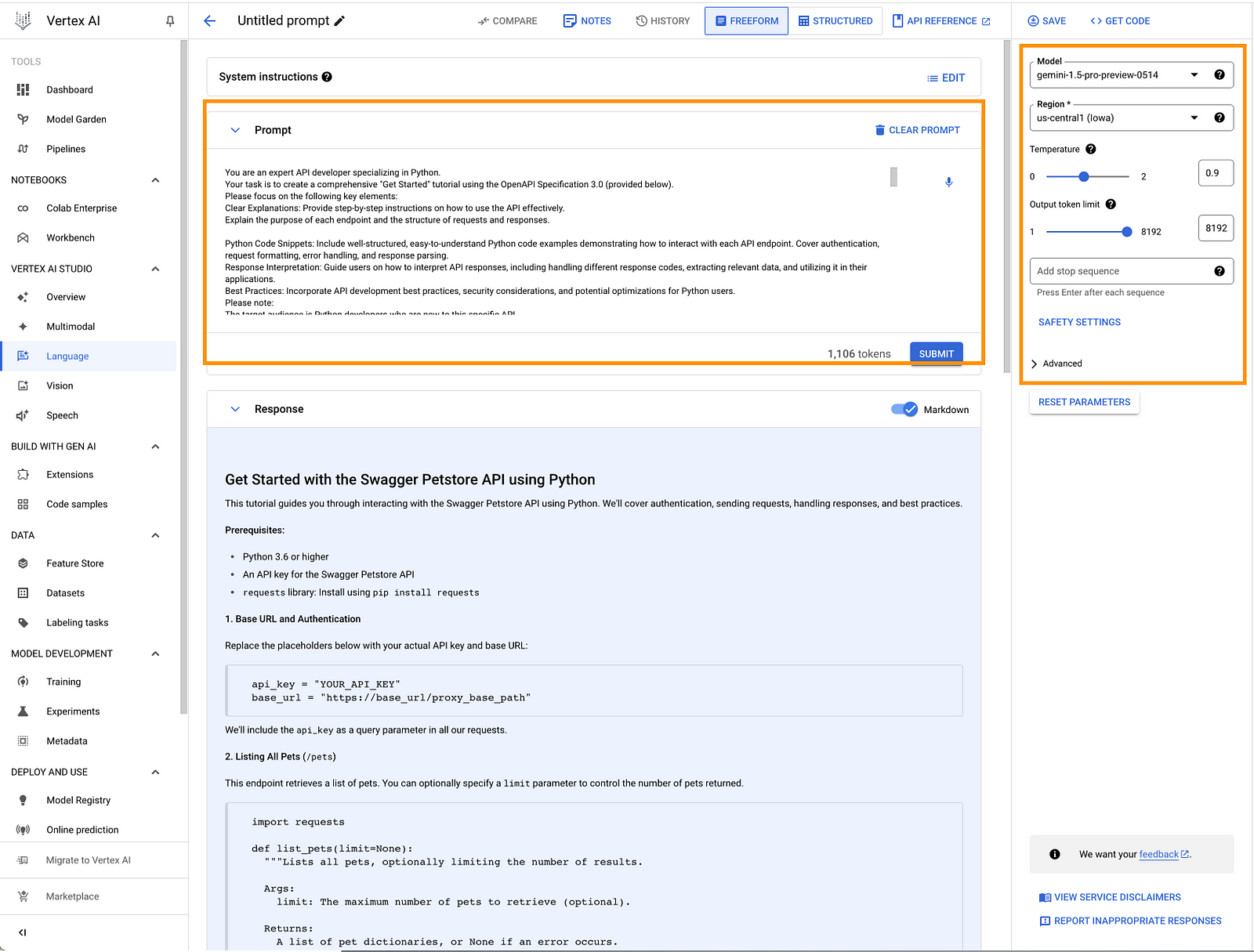
Once you are happy with the response of the model, click on “Get Code”.
Copy the Python code to your code editor. Mine looks as follows:
import base64
import vertexai
from vertexai.generative_models import GenerativeModel, Part, FinishReason
import vertexai.preview.generative_models as generative_models
def generate():
vertexai.init(project="PROJECT_ID", location="GCP_REGION") # Replace PROJECT_ID and GCP_REGION
model = GenerativeModel(
"gemini-1.5-pro-preview-0514",
)
responses = model.generate_content(
[text1],
generation_config=generation_config,
safety_settings=safety_settings,
stream=True,
)
for response in responses:
print(response.text, end="")
text1 = """You are an expert API developer specializing in Python.
Your task is to create a comprehensive \"Get Started\" tutorial using the OpenAPI Specification 3.0 (provided below).
Please focus on the following key elements:
Clear Explanations: Provide step-by-step instructions on how to use the API effectively.
Explain the purpose of each endpoint and the structure of requests and responses.
Python Code Snippets: Include well-structured, easy-to-understand Python code examples demonstrating how to interact with each API endpoint. Cover authentication, request formatting, error handling, and response parsing.
Response Interpretation: Guide users on how to interpret API responses, including handling different response codes, extracting relevant data, and utilizing it in their applications.
Best Practices: Incorporate API development best practices, security considerations, and potential optimizations for Python users.
Please note:
The target audience is Python developers who are new to this specific API.
Prioritize clarity, conciseness, and practical examples.
The tutorial should be self-contained, with minimal external dependencies.
OpenAPI Specification:
eploy your API proxy by clicking on “Deploy.”
Next, let’s update our OpenAPI specification by adding our Apigee API proxy’s endpoint (https://base_url/proxy_base_path). Additionally, we need to include a \"securityScheme\" in the OpenAPI Specification to indicate that an API key is required as a query parameter
Below is the final OpenAPI Specification that will be used in the next steps.
openapi: \"3.0.0\"
info:
version: 1.0.0
title: Swagger Petstore
license:
name: MIT
servers:
- url: https://base_url/proxy_base_path #REPLACE IT WITH YOUR PROXY ENDPOINT
paths:
/pets:
get:
summary: List all pets
operationId: listPets
tags:
- pets
security:
- ApiKeyAuth: []
parameters:
- name: limit
in: query
description: How many items to return at one time (max 100)
required: false
schema:
type: integer
maximum: 100
format: int32
responses:
\'200\':
description: A paged array of pets
headers:
x-next:
description: A link to the next page of responses
schema:
type: string
content:
application/json:
schema:
$ref: \"#/components/schemas/Pets\"
default:
description: unexpected error
content:
application/json:
schema:
$ref: \"#/components/schemas/Error\"
post:
summary: Create a pet
operationId: createPets
tags:
- pets
security:
- ApiKeyAuth: []
requestBody:
content:
application/json:
schema:
$ref: \'#/components/schemas/Pet\'
required: true
responses:
\'201\':
description: Null response
default:
description: unexpected error
content:
application/json:
schema:
$ref: \"#/components/schemas/Error\"
/pets/{petId}:
get:
summary: Info for a specific pet
operationId: showPetById
tags:
- pets
security:
- ApiKeyAuth: []
parameters:
- name: petId
in: path
required: true
description: The id of the pet to retrieve
schema:
type: string
responses:
\'200\':
description: Expected response to a valid request
content:
application/json:
schema:
$ref: \"#/components/schemas/Pet\"
default:
description: unexpected error
content:
application/json:
schema:
$ref: \"#/components/schemas/Error\"
components:
schemas:
Pet:
type: object
required:
- id
- name
properties:
id:
type: integer
format: int64
name:
type: string
tag:
type: string
Pets:
type: array
maxItems: 100
items:
$ref: \"#/components/schemas/Pet\"
Error:
type: object
required:
- code
- message
properties:
code:
type: integer
format: int32
message:
type: string
securitySchemes:
ApiKeyAuth: # Arbitrary name for the security scheme
type: apiKey
in: query # The API key will be sent as a query parameter
name: apikey"""
generation_config = {
"max_output_tokens": 8192,
"temperature": 0.9,
"top_p": 0.95,
}
safety_settings = {
generative_models.HarmCategory.HARM_CATEGORY_HATE_SPEECH: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_HARASSMENT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
}
generate()
Our goal is to adjust this code and run it as a Google Cloud Function. You can use Gemini to help with that!
Cloud Function
The cloud function we are developing and deploying will be triggered whenever a new OpenAPI Spec file is uploaded to our GCS bucket “my-api-specs.”
My Python Cloud Function’s code looks as follows:
import functions_framework
import vertexai
import yaml
import os
import logging
from google.cloud import storage
from vertexai.generative_models import GenerativeModel, Part, FinishReason
import vertexai.preview.generative_models as generative_models
# Load sensitive data from environment variables
PROJECT_ID = "PROJECT_ID" #REPALCE it with your own GCP project
GCP_REGION = "GCP_REGION" #REPALCE it with your GCP region
DEST_BUCKET = "DEST_BUCKET" #REPALCE it with your bucket name
DEST_FOLDER = "DEST_FOLDER" #REPALCE it with your destination folder in your DEST_BUCKET
# Generation configuration and safety settings
GENERATION_CONFIG = {
"max_output_tokens": 8192,
"temperature": 0.8, # Adjusted for slightly less creative output
"top_p": 0.95,
}
SAFETY_SETTINGS = {
generative_models.HarmCategory.HARM_CATEGORY_HATE_SPEECH: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_HARASSMENT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
}
@functions_framework.cloud_event
def generateApiTutos(cloud_event):
logging.info("Generating API tutorial...")
try:
data = cloud_event.data
bucket = data.get("bucket")
name = data.get("name")
if not bucket or not name:
raise ValueError("Missing bucket or file name in the event data.")
open_api_spec = read_yaml_from_gcs(bucket, name)
if open_api_spec:
tutorial_text = generate_tutorial(open_api_spec)
output_file_name = f"tutorial_{os.path.basename(name).replace('.yaml', '.md')}"
save_to_gcs(DEST_BUCKET, DEST_FOLDER, output_file_name, tutorial_text)
else:
logging.warning("No valid OpenAPI specification found.")
except Exception as e:
logging.exception(f"Error generating tutorial: {e}")
def generate_tutorial(open_api_spec):
vertexai.init(project=PROJECT_ID, location=GCP_REGION)
model = GenerativeModel("gemini-1.5-pro-preview-0409")
prompt_text = (
"You are an expert API developer specializing in Python. Your task is to "
"create a comprehensive 'Get Started' tutorial using the OpenAPI "
"Specification 3.0 (provided below). Please focus on the following "
"key elements:\n\n"
"- Clear Explanations: Provide step-by-step instructions on how to use "
"the API effectively. Explain the purpose of each endpoint and the "
"structure of requests and responses.\n\n"
"- Python Code Snippets: Include well-structured, easy-to-understand "
"Python code examples demonstrating how to interact with each API "
"endpoint. Cover authentication, request formatting, error handling, "
"and response parsing.\n\n"
"- Response Interpretation: Guide users on how to interpret API "
"responses, including handling different response codes, extracting "
"relevant data, and utilizing it in their applications.\n\n"
"- Best Practices: Incorporate API development best practices, security "
"considerations, and potential optimizations for Python users.\n\n"
"Please note:\n"
"- The target audience is Python developers who are new to this specific API.\n"
"- Prioritize clarity, conciseness, and practical examples.\n"
"- The tutorial should be self-contained, with minimal external dependencies.\n\n"
"OpenAPI Specification:\n\n"
)
prompt_part = Part.from_text(prompt_text)
spec_part = Part.from_text(open_api_spec)
responses = model.generate_content(
[prompt_part, spec_part],
generation_config=GENERATION_CONFIG,
safety_settings=SAFETY_SETTINGS,
stream=False,
)
return responses.text if responses else ""
def read_yaml_from_gcs(bucket_name, file_path):
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_path)
with blob.open("r") as f:
try:
data = yaml.safe_load(f)
return yaml.dump(data) # Return the YAML data as a string
except yaml.YAMLError as e:
print(f"Error parsing YAML: {e}")
return None
def save_to_gcs(bucket_name, folder_name, file_name, content):
"""Saves text content to a file in a GCS bucket."""
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
output_file = f"{folder_name}/{file_name}"
blob = bucket.blob(output_file)
blob.upload_from_string(content)
print(f"Saved tutorial to gs://{bucket_name}/{output_file}")
My requirements.txt file is shown below:
functions-framework==3.*
google-cloud-aiplatform
google-cloud-storage
PyYAML
I deployed my cloud function using Python 3.12 as the runtime. Make sure to choose “Cloud Storage” as the trigger, as shown below:
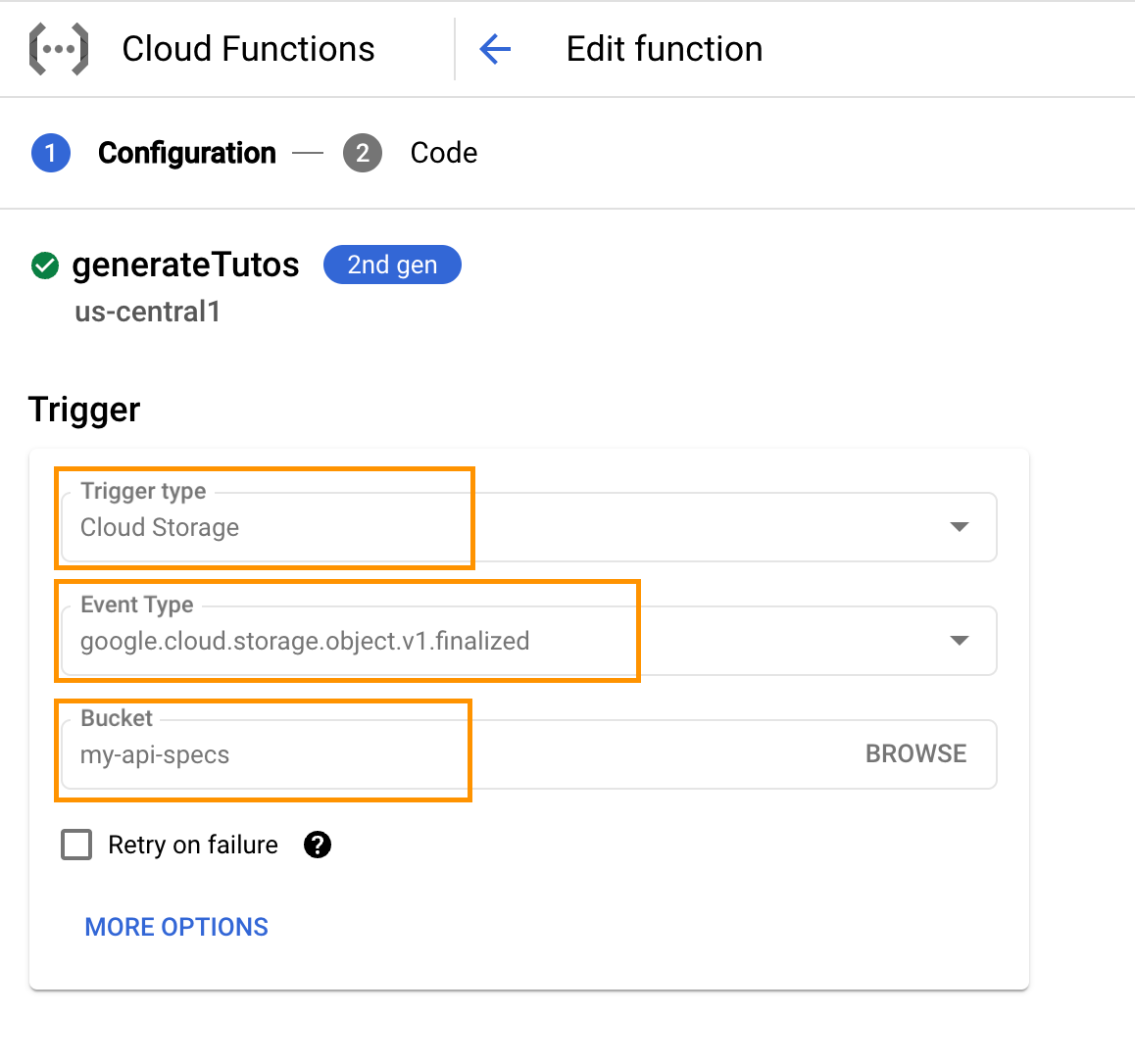
In summary, the code works as detailed below:
- Cloud Function Trigger: Our Cloud Function is triggered whenever a new OpenAPI specification file is uploaded to the bucket “my-api-specs”.
- Gemini 1.5 Pro Integration: The Cloud Function leverages Vertex AI’s Python SDK to interact with the Gemini 1.5 Pro generative AI model.
- Prompt Engineering: The code includes a detailed prompt that instructs the Gemini model to create comprehensive “Get Started” tutorials tailored to Python developers, focusing on clear explanations, code examples, response interpretation, and best practices.
- Tutorial Generation: The Cloud Function sends the OpenAPI specification and prompt to Gemini, which generates the tutorial text.
- Storage of Generated Tutorials: The generated tutorial is saved as a Markdown file in the “my-api-tutos” bucket.
- Error Handling and Logging: The code includes error handling to manage potential issues (like invalid YAML or generation failures) and logging for troubleshooting.
- Dependencies: The “requirements.txt” file lists the Python libraries needed for the Cloud Function, including
functions-framework,google-cloud-aiplatform,google-cloud-storage, andPyYAML. - Deployment: The Cloud Function is deployed with Python 3.12 as the runtime, and it’s configured to be triggered by changes in the “my-api-specs” bucket.
Note: I have used the Vertex AI Python SDK in this example, but the same implementation can be achieved using the Gemini API available in Google AI Studio.
Now, we are ready to test the whole workflow end-to-end.
Testing the whole setup
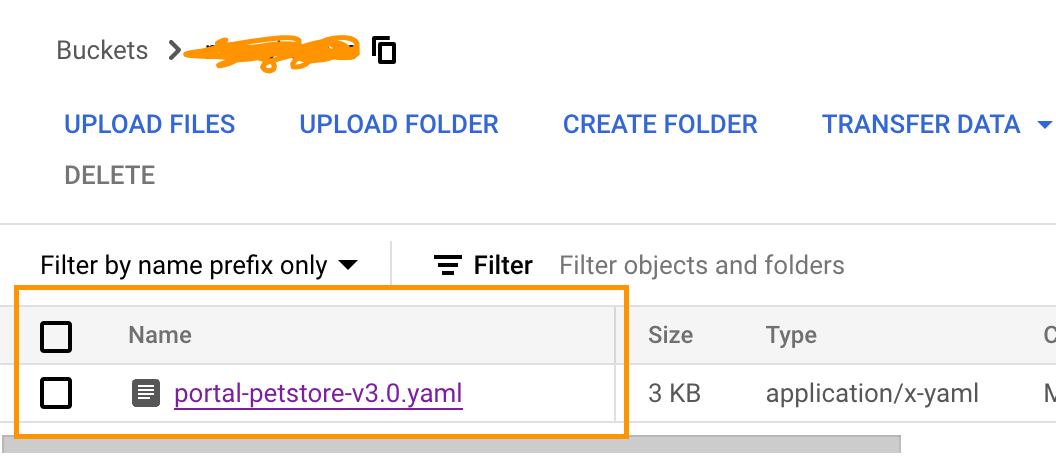
Testing the setup described in the section 3.3 above is pretty straightforward. You simply upload your Open API Spec(s) to your source GCP bucket (e.g., my-api-specs) and then check if a file (.md) is created in your destination bucket as shown below:
Source Bucket
Destination Bucket
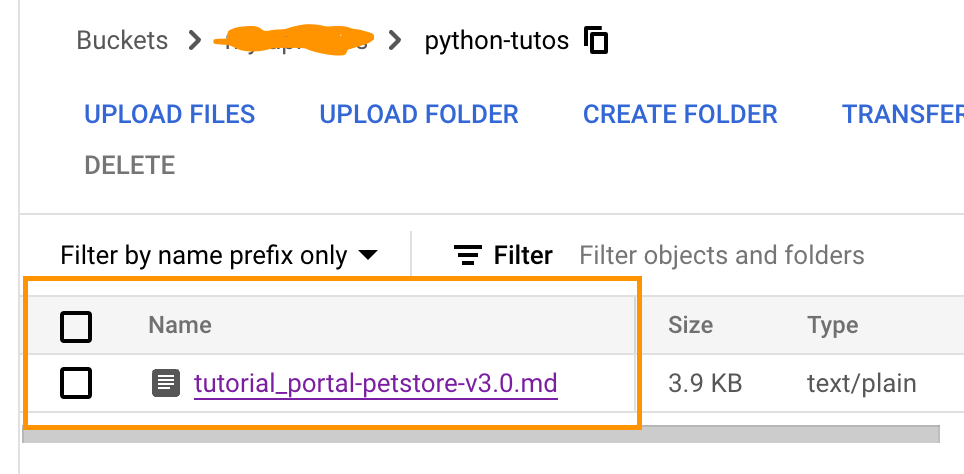
In my case, the content of the .md file looks as follows:
## Get Started with the Swagger Petstore API using Python
This tutorial will guide you through interacting with the Swagger Petstore API using Python.
We'll cover authentication, making requests, handling responses, and best practices.
**Prerequisites:**
* Python 3.6 or later
* An API key for the Petstore API
* `requests` library: Install using `pip install requests`
**1. Authentication**
The Petstore API uses API key authentication. You need to include your API key in the query parameter `apikey` for every request.
```python
API_KEY = 'YOUR_API_KEY' # Replace with your actual API key
BASE_URL = 'https://base_url/proxy_base_path' #REPLACE IT WITH YOUR PROXY ENDPOINT'
```
**2. Listing Pets (`/pets`)**
This endpoint retrieves a list of pets. You can optionally specify the `limit` parameter to control the number of pets returned per page.
```python
import requests
def list_pets(limit=20):
"""
Retrieves a list of pets.
Args:
limit: Maximum number of pets to return (default: 20)
Returns:
A list of pet dictionaries, or None if an error occurs.
"""
url = f'{BASE_URL}/pets?limit={limit}&apikey={API_KEY}'
response = requests.get(url)
if response.status_code == 200:
return response.json()
else:
print(f"Error fetching pets: {response.status_code} - {response.text}")
return None
# Example usage
pets = list_pets(limit=10)
if pets:
for pet in pets:
print(f"Pet ID: {pet['id']}, Name: {pet['name']}, Tag: {pet['tag']}")
```
**3. Creating a Pet (`/pets`)**
This endpoint allows you to add a new pet to the store.
```python
import requests
def create_pet(name, tag=None):
"""
Creates a new pet.
Args:
name: The name of the pet.
tag: An optional tag for the pet.
Returns:
True if the pet was created successfully, False otherwise.
"""
url = f'{BASE_URL}/pets?apikey={API_KEY}'
pet_data = {'name': name, 'tag': tag}
response = requests.post(url, json=pet_data)
if response.status_code == 201:
return True
else:
print(f"Error creating pet: {response.status_code} - {response.text}")
return False
# Example usage
if create_pet('Buddy', tag='Friendly'):
print('Pet created successfully!')
```
**4. Retrieving a Pet by ID (`/pets/{petId}`)**
This endpoint fetches a specific pet by its ID.
```python
import requests
def get_pet_by_id(pet_id):
"""
Retrieves a pet by its ID.
Args:
pet_id: The ID of the pet to retrieve.
Returns:
A dictionary containing the pet's information, or None if an error occurs.
"""
url = f'{BASE_URL}/pets/{pet_id}?apikey={API_KEY}'
response = requests.get(url)
if response.status_code == 200:
return response.json()
else:
print(f"Error fetching pet: {response.status_code} - {response.text}")
return None
# Example usage
pet = get_pet_by_id('123')
if pet:
print(f"Pet ID: {pet['id']}, Name: {pet['name']}, Tag: {pet['tag']}")
```
**5. Response Interpretation**
The API returns standard HTTP status codes to indicate success or failure.
* **200 OK:** The request was successful.
* **201 Created:** The resource was created successfully.
* **4xx Client Error:** There was an issue with your request (e.g., invalid parameters).
* **5xx Server Error:** The server encountered an error.
The response body will be in JSON format. You can use the `response.json()` method to parse it into a Python dictionary.
**6. Best Practices**
* **Error Handling:** Implement error handling to catch exceptions and handle unsuccessful API responses gracefully.
* **Security:** Store your API key securely and avoid exposing it in your code. Consider using environment variables.
* **Rate Limiting:** Be mindful of potential rate limits imposed by the API. Implement mechanisms to handle rate limiting if necessary.
This tutorial provides a basic foundation for interacting with the Swagger Petstore API. Remember to consult the complete OpenAPI specification for detailed information about all endpoints and their parameters.
Conclusion
The concept described in this post will allow you to automate the creation of user-friendly tutorials for new APIs, helping developers quickly understand and adopt them, ultimately leading to increased API adoption and a thriving developer ecosystem.
If you found this content useful, I’d love to hear your thoughts or feedback.
Note: this post was originally published in my Medium.com blog.